And so you know, we tested (thanks to Preben) ReFS integration even with encryption enabled, and it works. So you can receive encrypted backups from tenants and still leverage this new capability. I'm really excited too about the benefits that a service provider can gain using ReFS for Cloud Connect.
-
dellock6
- VeeaMVP
- Posts: 6220
- Liked: 2008 times
- Joined: Jul 26, 2009 3:39 pm
- Full Name: Luca Dell'Oca
- Location: Varese, Italy
- Contact:
Re: Veeam Next Big Thing - REFS
Yes, you can leverage ReFS integration even for Cloud Connect repositories. Otherwise in my role why would I be so interested in this topic? 
And so you know, we tested (thanks to Preben) ReFS integration even with encryption enabled, and it works. So you can receive encrypted backups from tenants and still leverage this new capability. I'm really excited too about the benefits that a service provider can gain using ReFS for Cloud Connect.
And so you know, we tested (thanks to Preben) ReFS integration even with encryption enabled, and it works. So you can receive encrypted backups from tenants and still leverage this new capability. I'm really excited too about the benefits that a service provider can gain using ReFS for Cloud Connect.
Luca Dell'Oca
Principal Cloud Architect @ Veeam Software
https://www.virtualtothecore.com/
https://github.com/dellock6/
Veeam VMCE #1
Principal Cloud Architect @ Veeam Software
https://www.virtualtothecore.com/
https://github.com/dellock6/
Veeam VMCE #1
-
WorkingHardInIt
- Veeam Vanguard
- Posts: 41
- Liked: 11 times
- Joined: Feb 14, 2014 1:27 pm
- Full Name: Didier Van Hoye
- Contact:
Re: Veeam Next Big Thing - REFS
For those looking for information of ReFS upgrade:
From Windows Server 2012 R2 (ReFs 1.2) to Windows 2016: ReFS is NOT upgraded (not by an in place upgrade and not by presenting an existing ReFS 1.2 LUN to a Windows Server 2016). Those already using ReFS or thinking about using ReFS on Windows Server 2012 R2 now for "future proofing" should know they'll have to do a data migration. You can keep your data on ReFS 1.2 and it's readable by Windows Server 2016 but you wont gain the great capabilities you're after.
An upgrade from Windows Server 2016 TPv5 (ReFS 3.0) to Windows 2016 RTM (ReFS 3.0 or 3.x?) is supported by MSFT. But just like Veeam B&R 9.5 Beta it's all just for testing & evaluation ... these are not RTM ready products.
I'm quite enthusiastic about it so I hope to move fast come RTM I have one repository at the ready with a LUN to be formatted with ReFS v3
That's my understanding for the moment.
From Windows Server 2012 R2 (ReFs 1.2) to Windows 2016: ReFS is NOT upgraded (not by an in place upgrade and not by presenting an existing ReFS 1.2 LUN to a Windows Server 2016). Those already using ReFS or thinking about using ReFS on Windows Server 2012 R2 now for "future proofing" should know they'll have to do a data migration. You can keep your data on ReFS 1.2 and it's readable by Windows Server 2016 but you wont gain the great capabilities you're after.
An upgrade from Windows Server 2016 TPv5 (ReFS 3.0) to Windows 2016 RTM (ReFS 3.0 or 3.x?) is supported by MSFT. But just like Veeam B&R 9.5 Beta it's all just for testing & evaluation ... these are not RTM ready products.
I'm quite enthusiastic about it so I hope to move fast come RTM I have one repository at the ready with a LUN to be formatted with ReFS v3
That's my understanding for the moment.
-
Delo123
- Veteran
- Posts: 361
- Liked: 109 times
- Joined: Dec 28, 2012 5:20 pm
- Full Name: Guido Meijers
- Contact:
Re: Veeam Next Big Thing - REFS
I guess it depends per environment:dellock6 wrote: On the topic of data reduction, whatever type of job you are running, the savings are all going to be there, let me explain:
- any incremental backup during a day has almost unique data, so chances to be reduced by deduplication are lower. Dedupe will not help here just like ReFS will not help
I'm honestly wondering if deduplication will be needed AT ALL with this new technology, especially when you add to the discussion the "restore" performance. ReFS is not deduped, so there's nothing to re-hydrate during the restore.
Code: Select all
PS C:\Windows\system32> get-dedupstatus
FreeSpace SavedSpace OptimizedFiles InPolicyFiles Volume
--------- ---------- -------------- ------------- ------
51.79 TB 68.14 TB 357 357 O:
46.54 TB 87.42 TB 6996 6996 R:
52.17 TB 24.88 TB 9 9 S:
49.32 TB 55.01 TB 325 356 Q:
51.47 TB 43.11 TB 4096 4096 P:
42.6 TB 51.9 TB 163 163 T:
57.46 TB 34.06 TB 3326 3326 V:
-
SBarrett847
- Service Provider
- Posts: 315
- Liked: 41 times
- Joined: Feb 02, 2016 5:02 pm
- Full Name: Stephen Barrett
- Contact:
Re: Veeam Next Big Thing - REFS
That's Awesome! But I can't see how this would work for Encrypted data though. I'm glad it does, I don't understand how though.dellock6 wrote:Yes, you can leverage ReFS integration even for Cloud Connect repositories. Otherwise in my role why would I be so interested in this topic?
And so you know, we tested (thanks to Preben) ReFS integration even with encryption enabled, and it works. So you can receive encrypted backups from tenants and still leverage this new capability. I'm really excited too about the benefits that a service provider can gain using ReFS for Cloud Connect.
-
veremin
- Product Manager
- Posts: 20752
- Liked: 2415 times
- Joined: Oct 26, 2012 3:28 pm
- Full Name: Vladimir Eremin
- Contact:
Re: Veeam Next Big Thing - REFS
Correct, though, it would require new versions of both VB&R and EP.does it also work for Endpoint Jobs and Endpoit Copy Jobs when target is a B&R Repo with REFS?
-
dellock6
- VeeaMVP
- Posts: 6220
- Liked: 2008 times
- Joined: Jul 26, 2009 3:39 pm
- Full Name: Luca Dell'Oca
- Location: Varese, Italy
- Contact:
Re: Veeam Next Big Thing - REFS
It's the same reason making synthetic operations work when encryption is enabled. Remember, our encryption is transparent to ourselves; during transform operations Veeam datamover can correctly identify required blocks regardless of their encryption status (as our encryption is done block by block anyway, Veeam backups are not managed as a single monolithic binary stream) and "post" them into the new full backup file. But instead of actually writing the block to disk, we just tell ReFS to reference the existing block already present on the volume.SBarrett847 wrote:That's Awesome! But I can't see how this would work for Encrypted data though. I'm glad it does, I don't understand how though.
Luca
Luca Dell'Oca
Principal Cloud Architect @ Veeam Software
https://www.virtualtothecore.com/
https://github.com/dellock6/
Veeam VMCE #1
Principal Cloud Architect @ Veeam Software
https://www.virtualtothecore.com/
https://github.com/dellock6/
Veeam VMCE #1
-
Gostev
- former Chief Product Officer (until 2026)
- Posts: 33084
- Liked: 8186 times
- Joined: Jan 01, 2006 1:01 am
- Location: Baar, Switzerland
- Contact:
Re: Veeam Next Big Thing - REFS
Indeed, support for "deduplicating" encrypted backups is really the killer feature of our ReFS integration, and this is something neither external deduplicating storage nor Windows Server dedupe are able to do (and will never be able to). This is really a game changer, especially for Cloud Connect service providers.
-
pesos
- Veteran
- Posts: 257
- Liked: 36 times
- Joined: Nov 12, 2014 9:40 am
- Full Name: John Johnson
- Contact:
Re: Veeam Next Big Thing - REFS
I apologize for my noobishness - still trying to get my head wrapped around all of this and figuring out the best way to proceed...
We have a 2-node server 2016 hyper-v cluster with shared SAS primary storage and I've configured our b&r repository on a second shared SAS array. Source is a CSV which is ntfs-formatted (so we can use windows dedupe) and the repository array is REFSv3 formatted.
I am configuring on-host jobs so that the primary host can write directly from source to target but I'm trying to decide if we should be using per-vm backup files or not... We have a few exchange servers (different databases), a few file servers (different file stores), a few DCs (different domains) and a few skype for business servers and other miscellaneous small VMs.
Also trying to figure out if there is any reason to not do reverse incremental in this scenario...
Thanks all!
We have a 2-node server 2016 hyper-v cluster with shared SAS primary storage and I've configured our b&r repository on a second shared SAS array. Source is a CSV which is ntfs-formatted (so we can use windows dedupe) and the repository array is REFSv3 formatted.
I am configuring on-host jobs so that the primary host can write directly from source to target but I'm trying to decide if we should be using per-vm backup files or not... We have a few exchange servers (different databases), a few file servers (different file stores), a few DCs (different domains) and a few skype for business servers and other miscellaneous small VMs.
Also trying to figure out if there is any reason to not do reverse incremental in this scenario...
Thanks all!
-
barryCairns
- Novice
- Posts: 3
- Liked: never
- Joined: Nov 12, 2015 8:49 am
- Full Name: Barry Cairns
- Contact:
Re: Veeam Next Big Thing - REFS
I am also looking into using 9.5 with REFS on 2016, however I am not seeing any of the spaceless full backup advantages that have been highlighted.
I have the same job running in parelel on two servers. one is 2012 goig to a dedupe repository. The other is a 2016 server with several REFS volumes. The jobs run every 30 mins. one on the 2012 box and one on the 2016 box. The jobs is set to also do daily synthetic fulls. As if my understanding is correct I should see the see some advantages in keeping these synthetics on REFS as it's the same blocks for the most part in the full.
I am however not seeing any capacity savings at all. I do see improvement in the transform jobs but not in capacity. Also my space used on the volumes shows as larger than the size of the backup repository. Freshly formatted they show 150GB used space. Even accounting for the 150gb used space my space used exceeds the folder size +the 150GB. I am struggling to see why I am not getting the savings I would have aticipated???
The used space on the dedupe volume is 4.5GB space on disk, space used is 51GB so quite a saving. I would have also expected to see a reduction in the backup size due to the synthetics included as part of the job.
Can anybody who has implemented this give me any pointers. As its looking like a no case of sticking with dedupe as the capacity savings are greater than the benefits in transform time. If I was however getting the spaceless full advantages it would be beneficial.
Have i not configured something I should have?? Any help or advice appreciated?
I have the same job running in parelel on two servers. one is 2012 goig to a dedupe repository. The other is a 2016 server with several REFS volumes. The jobs run every 30 mins. one on the 2012 box and one on the 2016 box. The jobs is set to also do daily synthetic fulls. As if my understanding is correct I should see the see some advantages in keeping these synthetics on REFS as it's the same blocks for the most part in the full.
I am however not seeing any capacity savings at all. I do see improvement in the transform jobs but not in capacity. Also my space used on the volumes shows as larger than the size of the backup repository. Freshly formatted they show 150GB used space. Even accounting for the 150gb used space my space used exceeds the folder size +the 150GB. I am struggling to see why I am not getting the savings I would have aticipated???
The used space on the dedupe volume is 4.5GB space on disk, space used is 51GB so quite a saving. I would have also expected to see a reduction in the backup size due to the synthetics included as part of the job.
Can anybody who has implemented this give me any pointers. As its looking like a no case of sticking with dedupe as the capacity savings are greater than the benefits in transform time. If I was however getting the spaceless full advantages it would be beneficial.
Have i not configured something I should have?? Any help or advice appreciated?
-
Gostev
- former Chief Product Officer (until 2026)
- Posts: 33084
- Liked: 8186 times
- Joined: Jan 01, 2006 1:01 am
- Location: Baar, Switzerland
- Contact:
Re: Veeam Next Big Thing - REFS
Well this is not normal for any file system, looks like something is seriously wrong in your setup. Please open a support case to investigate.barryCairns wrote:Also my space used on the volumes shows as larger than the size of the backup repository.
-
Gostev
- former Chief Product Officer (until 2026)
- Posts: 33084
- Liked: 8186 times
- Joined: Jan 01, 2006 1:01 am
- Location: Baar, Switzerland
- Contact:
Re: Veeam Next Big Thing - REFS
FYI, here's how spaceless full backup advantages can normally be observed: total size of backup files is way smaller than used space on the volume.
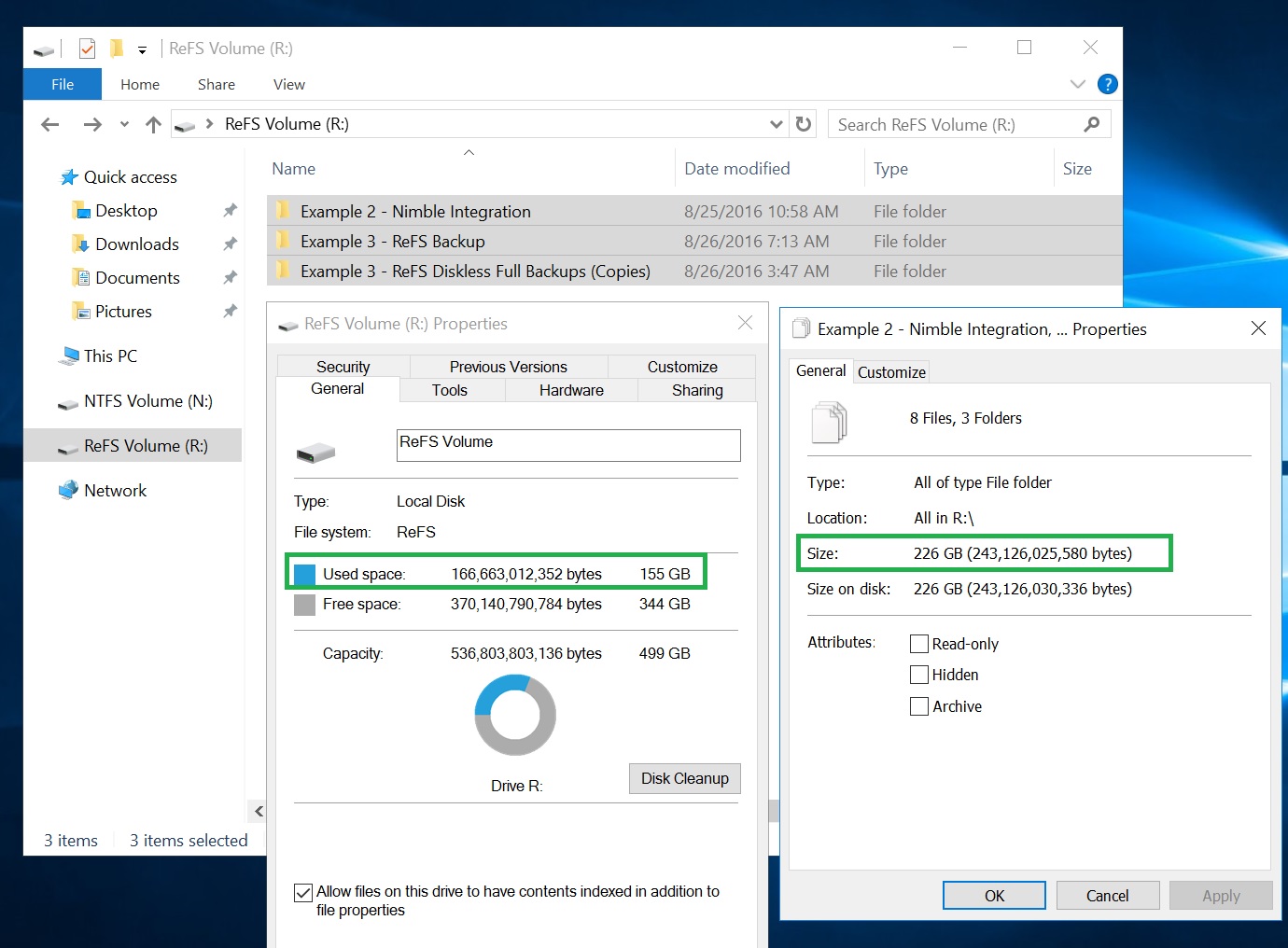{kind=link}
-
foggy
- Veeam Software
- Posts: 21222
- Liked: 2184 times
- Joined: Jul 11, 2011 10:22 am
- Full Name: Alexander Fogelson
- Contact:
Re: Veeam Next Big Thing - REFS
Barry, please also review this thread for additional information.
-
matt_778
- Enthusiast
- Posts: 27
- Liked: 2 times
- Joined: Feb 08, 2010 9:25 am
- Full Name: Matt
- Contact:
Re: Veeam Next Big Thing - REFS
Can someone clarify something - The REFS benefits have been mentioned when using synthetic full backup jobs.
Do we gain the space efficiencies on GFS Backup Copy jobs? Are these weekly, monthly, yearly points also considered synthetic full, and so reap the same benefits?
Thanks
Do we gain the space efficiencies on GFS Backup Copy jobs? Are these weekly, monthly, yearly points also considered synthetic full, and so reap the same benefits?
Thanks
-
Gostev
- former Chief Product Officer (until 2026)
- Posts: 33084
- Liked: 8186 times
- Joined: Jan 01, 2006 1:01 am
- Location: Baar, Switzerland
- Contact:
Re: Veeam Next Big Thing - REFS
Yes. GFS full backup archive produced by Backup Copy job is where you will see the most benefit from the spaceless full backup technology.
Who is online
Users browsing this forum: Google Adsense [Bot], Semrush [Bot] and 1750 guests