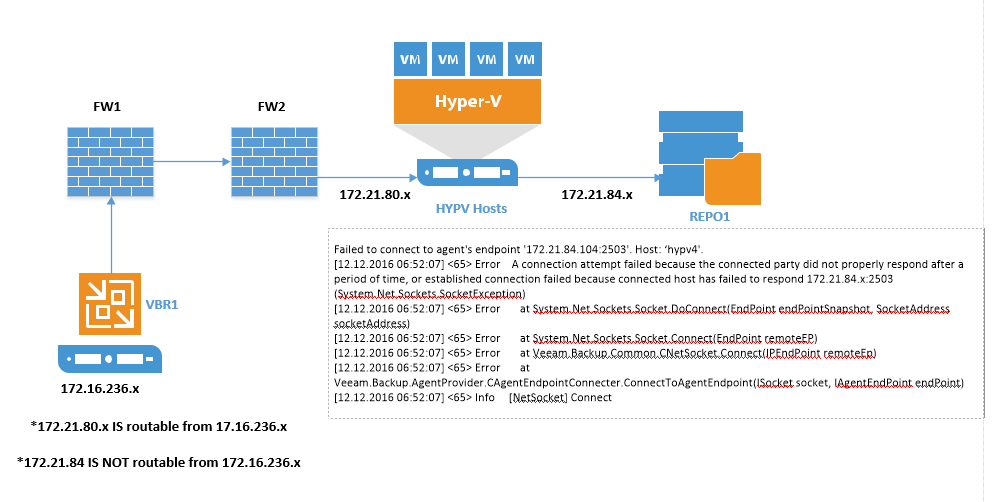
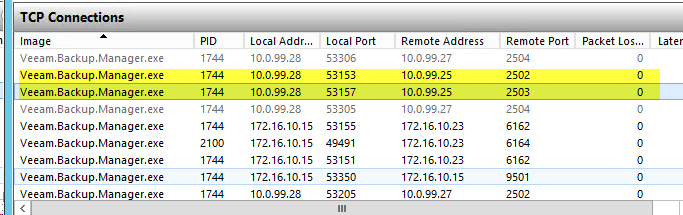
I have noticed that there is a real delay in jobs starting when utilising multiple NICS and preferred networks in Veeam. Let me give you a break down of my current setup and what the issue is.
VEEAM01 (Management Server). IP address 172.16.10.15
VEEAMREPO01 (Proxy / ReFS repository). IP address 172.16.10.23, 10.0.99.25, 10.0.99.26
VEEAMVSAN1 (Proxy) . IP address 172.16.10.14, 10.0.99.27
The 172.16.10.x is a /16 network and is acting as the management network. The 10.0.99.x /24 network is the data network used for backup traffic. 10.0.99.x /24 is not routable.
My assumption is that the VBR management server should be able to co-ordinate jobs on the proxy and repository servers to utilise the 10.0.99.x network without it needing to be able to talk to the 10.0.99.x network. Is this assumption correct?
What I have found is a ton of errors in the task log similar to below
Code: Select all
.2016 18:33:27] <52> Error Failed to connect to agent's endpoint '10.0.99.27:2505'. Host: 'VeeamVSAN1'.
[19.12.2016 18:33:27] <52> Error A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond 10.0.99.27:2505 (System.Net.Sockets.SocketException)
[19.12.2016 18:33:27] <52> Error at System.Net.Sockets.Socket.DoConnect(EndPoint endPointSnapshot, SocketAddress socketAddress)
[19.12.2016 18:33:27] <52> Error at System.Net.Sockets.Socket.Connect(EndPoint remoteEP)
[19.12.2016 18:33:27] <52> Error at Veeam.Backup.Common.CNetSocket.Connect(IPEndPoint remoteEp)
[19.12.2016 18:33:27] <52> Error at Veeam.Backup.AgentProvider.CAgentEndpointConnecter.ConnectToAgentEndpoint(ISocket socket, IAgentEndPoint endPointAs a test I added an additional NIC to the VEEAM01 (management server) on the 10.0.99.x subnet an re ran a job. Low and behold the job started pretty much instantly. A couple of test jobs I re-ran have ran 80% quicker because there are no errors in the task log anymore as above.
So the question is, WHY does the proxy need to establish a connection with the management server on the preferred network that is assigned for data moving?
A colleague of mine is having a very similar issue, case ID 02002661.
My environment is VMware, his is Hyper V.
Thanks,
Ian