For a few weeks I've noticed unusual reads during backup. Something (Resource monitor says it's "System" but I suspect that its actually Veeam proxy process) heavily reads VIB files during backup, several times more than backup write throughput (40-120MB/s write vs 140-330MB/s read). It's enough to actually limit backup performance as RAID array maxes out around 4-500MB/s.
It's not backup merge, as this gets triggered later and consumes almost no IO (ReFS).
I also applied 9.5U4a just in case but no change.
I have not yet contacted support, thought that someone might have seen it in forums.
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
-
foggy
- Veeam Software
- Posts: 21222
- Liked: 2184 times
- Joined: Jul 11, 2011 10:22 am
- Full Name: Alexander Fogelson
- Contact:
Re: Unusual read IO on backup repository during backup
I'd open a case to take a closer look. Is it a regular backup job, not backup copy? No other activity involving repository at this time?
-
HannesK
- Product Manager
- Posts: 16219
- Liked: 3700 times
- Joined: Sep 01, 2014 11:46 am
- Full Name: Hannes Kasparick
- Location: Austria
- Contact:
Re: Unusual read IO on backup repository during backup
Hello,
if it's system, then I would not expect Veeam to be the real reason (although it happens at the same time). VeeamAgent.exe (don't mix up with Veeam Agent for Windows!) is the process writing to disk. Here an example output.

Best regards,
Hannes
if it's system, then I would not expect Veeam to be the real reason (although it happens at the same time). VeeamAgent.exe (don't mix up with Veeam Agent for Windows!) is the process writing to disk. Here an example output.
Best regards,
Hannes
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
Only regular backup jobs.
It might have been VeeamAgent.exe - I wrote the post from memory. My suspicion about System really being VeeamAgent is because Windows sometimes bills IO to kernel instead of the real process. Not sure why but it's usually due to some kind of redirection/reprocessing in IO stack (for example deduplication).
I'll create the support issue if I can work out a way to explain this strange issue to support...
It might have been VeeamAgent.exe - I wrote the post from memory. My suspicion about System really being VeeamAgent is because Windows sometimes bills IO to kernel instead of the real process. Not sure why but it's usually due to some kind of redirection/reprocessing in IO stack (for example deduplication).
I'll create the support issue if I can work out a way to explain this strange issue to support...
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
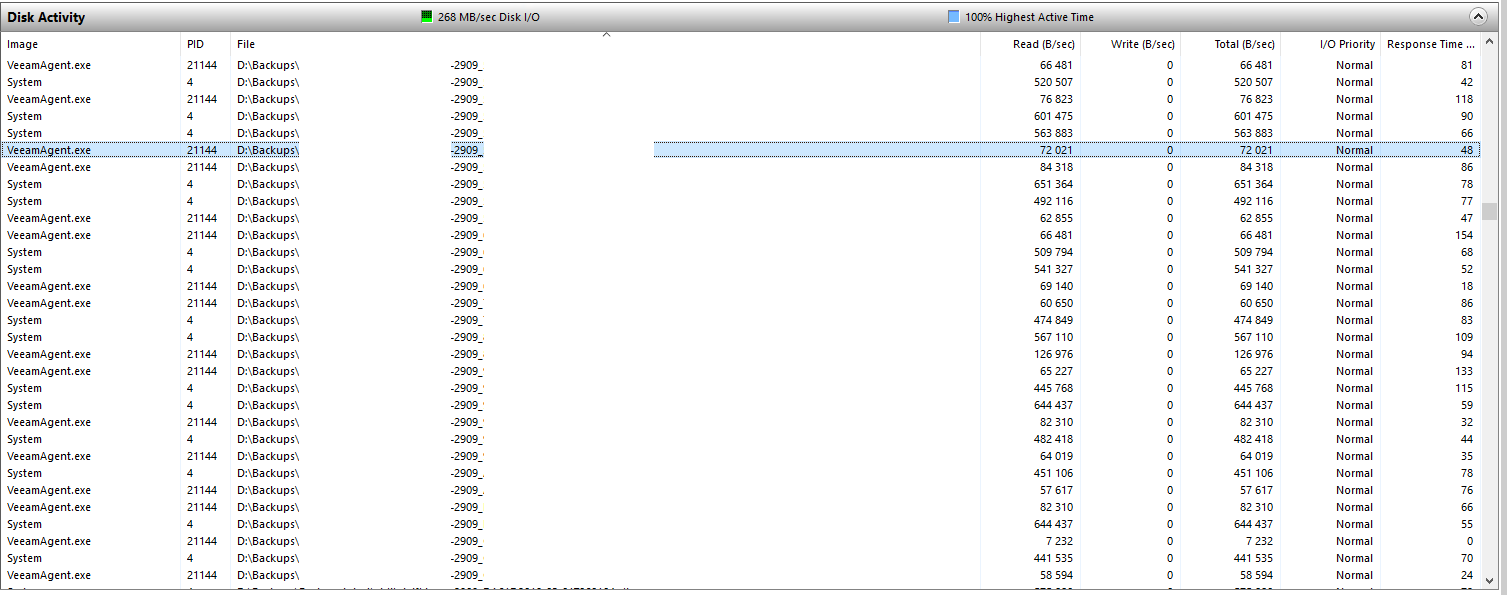
I made a few screenshots for support ticket but I thought I'd share them here for illustration.
Top IO throughtput, all reads are various VIB files of different VMs (per-VM chains are used). A few writes are actual backup writes.
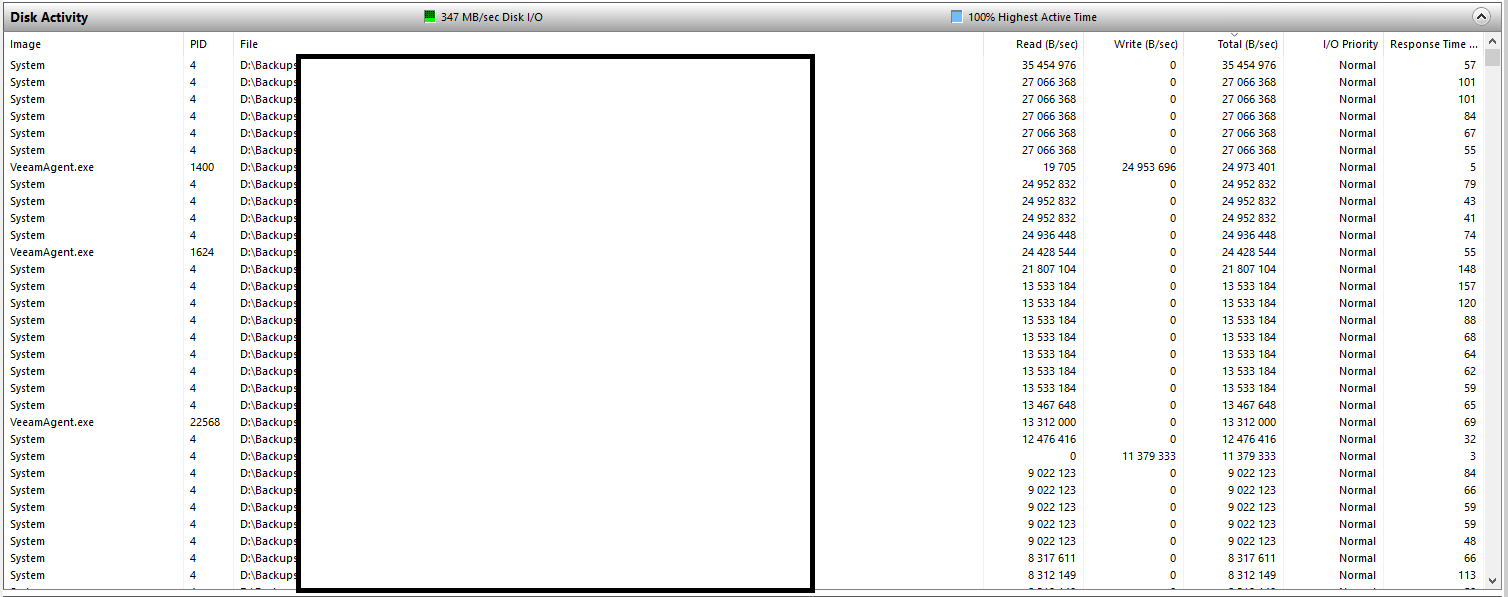
When sorting by file name, VIBs of the same VM are being read, billed to both VeeamAgent and System.
Top IO throughtput, all reads are various VIB files of different VMs (per-VM chains are used). A few writes are actual backup writes.
When sorting by file name, VIBs of the same VM are being read, billed to both VeeamAgent and System.
-
HannesK
- Product Manager
- Posts: 16219
- Liked: 3700 times
- Joined: Sep 01, 2014 11:46 am
- Full Name: Hannes Kasparick
- Location: Austria
- Contact:
Re: Unusual read IO on backup repository during backup
hmm just guessing, health check? compact full?
also suggest to open a case if that's not the case.
also suggest to open a case if that's not the case.
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
#03513640 going nowhere.
Ran ProcMon during backup run and VeeamAgent processes read ~55GB during 3 minute capture at the start of backup window (no health check, no compact, no synthetic full etc). It seems that Veeam tries to read at least 20MB up to 1GB from each incremental file in chain (just took a look at a few examples). Judging by monitoring graphs (average * time), there's ~500GB of reads for ~50GB of writes during each backup run.
Ran ProcMon during backup run and VeeamAgent processes read ~55GB during 3 minute capture at the start of backup window (no health check, no compact, no synthetic full etc). It seems that Veeam tries to read at least 20MB up to 1GB from each incremental file in chain (just took a look at a few examples). Judging by monitoring graphs (average * time), there's ~500GB of reads for ~50GB of writes during each backup run.
-
foggy
- Veeam Software
- Posts: 21222
- Liked: 2184 times
- Joined: Jul 11, 2011 10:22 am
- Full Name: Alexander Fogelson
- Contact:
Re: Unusual read IO on backup repository during backup
It reads metadata from all restore points in the chain - how long is the chain btw?
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
140 restore points.
-
foggy
- Veeam Software
- Posts: 21222
- Liked: 2184 times
- Joined: Jul 11, 2011 10:22 am
- Full Name: Alexander Fogelson
- Contact:
Re: Unusual read IO on backup repository during backup
For each 1 TB of stored VM data Veeam B&R stores ~300 MB of metadata (for the default 1 MB block size). The entire backup chain is opened when the job starts, so you can estimate the size of data that is read from the target repository during each job run.
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
There's about 18TB of data in repository (~5-6TB original data) with WAN (256kB?) block size.
That's 18*300*4 (four times smaller block size) =~21-22GB.
Unfortunately I've been unable to progress with SR due to some high-priority tasks, but I'll try to get back to it ASAP.
That's 18*300*4 (four times smaller block size) =~21-22GB.
Unfortunately I've been unable to progress with SR due to some high-priority tasks, but I'll try to get back to it ASAP.
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
It has been suggested by support that this is normal so I took a deeper look into this.
I took some more exact measurements with ProcMon, recording only reads by VeeamAgent to repository to keep log file size reasonable. This should exclude reads from SAN ( we use direct SAN mode) and exclude any OS read-ahead (as ProcMon shows only read commands by process).
Job 1
Processed 2,2TB
Read 47GB
Transferred 16,2GB
6,2TB in repository
54 VMs
140 restore points
According to foggy, there should be 6,2TB*300MB=~1860MB of metadata read if we used default block size of 1MB. As we use 256KB, it should be roughly 4 times larger, 7440MB.
ProcMon shows 311GiB of logical reads, a difference of nearly 40 times.
Job 2
Processed 3,6TB
Read 87,8GB
Transferred 24,8GB
9,47TB in repository
50 VMs
140 restore points
According to foggy, there should be 9,47TB*300MB=~2,841MB of metadata read if we used default block size of 1MB. As we use 256KB, it should be roughly 4 times larger, 11364MB.
ProcMon shows 540GB of logical reads, a difference of 50 times.
For comparison, I also recorded reads on another system that was set up recently and has nearly identical configuration.
Job 3
Processed 3,3TB
Read 220,5GB
Transferred 88,1GB
6,06TB in repository
78 VMs
140 restore points. As this system was setup only a few weeks ago, none of the VMs have 140 restore points yet and most have much less.
6,06*300MB=~1818MB*4=~7272MB. Actual logical reads 197GB. Difference of 28 times, but as chains are shorter, that might be expected.
Well... trends look similar.
Sure, some of these reads seem to be cached, so they don't actually hit the disk (I'd say roughly 35-60% is cached reads, depending on job). However these differences are still huge. 850GB of reads to store 42GB of incremental data (~20* read amplification)...?
Am I hitting some kind of edge case or just expecting too much and WAN block size with long chains is just horrible?
I took some more exact measurements with ProcMon, recording only reads by VeeamAgent to repository to keep log file size reasonable. This should exclude reads from SAN ( we use direct SAN mode) and exclude any OS read-ahead (as ProcMon shows only read commands by process).
Job 1
Processed 2,2TB
Read 47GB
Transferred 16,2GB
6,2TB in repository
54 VMs
140 restore points
According to foggy, there should be 6,2TB*300MB=~1860MB of metadata read if we used default block size of 1MB. As we use 256KB, it should be roughly 4 times larger, 7440MB.
ProcMon shows 311GiB of logical reads, a difference of nearly 40 times.
Job 2
Processed 3,6TB
Read 87,8GB
Transferred 24,8GB
9,47TB in repository
50 VMs
140 restore points
According to foggy, there should be 9,47TB*300MB=~2,841MB of metadata read if we used default block size of 1MB. As we use 256KB, it should be roughly 4 times larger, 11364MB.
ProcMon shows 540GB of logical reads, a difference of 50 times.
For comparison, I also recorded reads on another system that was set up recently and has nearly identical configuration.
Job 3
Processed 3,3TB
Read 220,5GB
Transferred 88,1GB
6,06TB in repository
78 VMs
140 restore points. As this system was setup only a few weeks ago, none of the VMs have 140 restore points yet and most have much less.
6,06*300MB=~1818MB*4=~7272MB. Actual logical reads 197GB. Difference of 28 times, but as chains are shorter, that might be expected.
Well... trends look similar.
Sure, some of these reads seem to be cached, so they don't actually hit the disk (I'd say roughly 35-60% is cached reads, depending on job). However these differences are still huge. 850GB of reads to store 42GB of incremental data (~20* read amplification)...?
Am I hitting some kind of edge case or just expecting too much and WAN block size with long chains is just horrible?
-
foggy
- Veeam Software
- Posts: 21222
- Liked: 2184 times
- Joined: Jul 11, 2011 10:22 am
- Full Name: Alexander Fogelson
- Contact:
Re: Unusual read IO on backup repository during backup
What was the engineer's argumentation behind this?It has been suggested by support that this is normal so I took a deeper look into this.
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
Copy-paste from last reply
That's now second engineer assigned to the case, I'm not sure if it got escalated or just reassigned.Here is what I found so far:
Most of his time differences are related to the data transfer, not the job processing (i.e., Merge).
1. As for ReFS with Data deduplication, we can see not that high IO since system needed to deduplicate data before storing.
2. As for ReFS without deduplication, we have IO spikes as we read from parts of the volume metadata, as we may have repeat blocks that can be fast cloned instead of writing a new block.
Metadata has its size and reading from this file just requires a lot of IO load to the system, like mentioned in the forums post you've shared with me.
veeam-backup-replication-f2/unusual-rea ... ml#p329627
I don't see something very suspicious in current configuration which might highly affect performance, so I'd say that performance in expected limits.
Please, inform me if you have any further questions.
-
HannesK
- Product Manager
- Posts: 16219
- Liked: 3700 times
- Joined: Sep 01, 2014 11:46 am
- Full Name: Hannes Kasparick
- Location: Austria
- Contact:
Re: Unusual read IO on backup repository during backup
Hello,
as far as I understood the case, you are working with Windows deduplication. Is that correct? If yes, did you already try a "normal" configuration without Windows deduplication?
Best regards,
Hannes
as far as I understood the case, you are working with Windows deduplication. Is that correct? If yes, did you already try a "normal" configuration without Windows deduplication?
Best regards,
Hannes
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
No deduplication (any more). Deduplication was only initially enabled after chain restart. We evaluated performance with some small jobs (larger jobs were deduplicated as well but didn't have enough restore points to trigger merges) and found no advantages over NTFS with deduplication.
Then deduplication was disabled, all files rehydrated and reads started increasing.
On the secondary system (in another country), deduplication was never enabled but I can see that reads are increasing as more restore points accumulate and VMs get migrated. I think it'll eventually hit similar repository read bottleneck problem.
I'm considering some options to reconfigure jobs as there has been little progress on this case:
* Regular synthetic fulls that should keep chains shorter and therefor reduce reads. Block size likely will remain the same as otherwise incrementals will not fit.
* Go back to deduplication (maybe with regular fulls) and accept slower restore times. On the benefit side, disk requirements go down.
Then deduplication was disabled, all files rehydrated and reads started increasing.
On the secondary system (in another country), deduplication was never enabled but I can see that reads are increasing as more restore points accumulate and VMs get migrated. I think it'll eventually hit similar repository read bottleneck problem.
I'm considering some options to reconfigure jobs as there has been little progress on this case:
* Regular synthetic fulls that should keep chains shorter and therefor reduce reads. Block size likely will remain the same as otherwise incrementals will not fit.
* Go back to deduplication (maybe with regular fulls) and accept slower restore times. On the benefit side, disk requirements go down.
-
DonZoomik
- Veteran
- Posts: 380
- Liked: 126 times
- Joined: Nov 25, 2016 1:56 pm
- Full Name: Mihkel Soomere
- Contact:
Re: Unusual read IO on backup repository during backup
In conclusion:
- ReFS block clone is much more read intensive (reads from backup repository) than other filesystems/repository types. According to support it will try to clone blocks from all previous restore points (instead of rereading from SAN, as I understand) and that creates quite a lot of read IO, much more than for example NTFS.
- Defragmentation task is occasionally broken on Windows 2016/2019 (on various servers, scheduled task does nothing and defrag never runs). In my case after letting defrag run for about a week (and manually creating a separate scheduled task), job execution times dropped by 30-50% (70-80 minutes -> 40-50 minute range).
Who is online
Users browsing this forum: Amazon [Bot], Semrush [Bot] and 183 guests